Spring 2026 GenAI Code Security Update: Despite Claims, AI Models Are Still Failing Security

The last six months have been nothing short of revolutionary for AI-powered coding. OpenAI‘s “Code Red” release brought us GPT-5.1 and 5.2. Google unveiled Gemini 3 with its touted “unprecedented reasoning capabilities.” Anthropic rolled out Claude 4.5 and 4.6, powering the increasingly ubiquitous Claude Code features. Enterprise adoption of tools like OpenClaw has exploded, with developers praising unprecedented productivity gains.
There’s just one problem: these models still can’t write secure code.
While AI coding assistants now achieve syntax correctness rates exceeding 95%, our latest testing reveals that security pass rates remain stubbornly stuck at approximately 55% – virtually identical to where they stood two years ago. In other words, despite the marketing hype and genuine functional improvements, nearly half of all AI-generated code contains known security vulnerabilities when no security guidance is explicitly provided.
As organizations rush to integrate AI coding assistants into their development workflows, they may be inadvertently scaling security debt at an unprecedented rate. This isn’t just a technical problem; it’s a systemic one that threatens to undermine the very productivity gains these tools promise.
Our Methodology: Consistent, Rigorous, Real-World
Since our 2025 GenAI Code Security Report, Veracode has maintained a consistent testing framework to measure the security properties of AI-generated code across multiple dimensions. Our approach is deliberately straightforward: we want to know what these models do “out of the box,” without any security-specific prompting or guidance.
The Test Setup:
- 80 coding tasks spanning common development scenarios
- 4 programming languages: Java, JavaScript, C#, and Python
- 4 critical vulnerability types (CWEs): SQL Injection (CWE-89), Cross-Site Scripting (CWE-80), Log Injection (CWE-117), and Insecure Cryptographic Algorithms (CWE-327)
- 5 task instances for each language-CWE combination
Each task involves completing a function based on a comment describing the desired functionality. Critically, the requested functionality can be implemented in either a secure or insecure way. We then run Veracode’s SAST tool on the generated code to detect the presence of known vulnerabilities.
For this Spring 2026 update, we tested the latest flagship models from every major vendor, with particular emphasis on the most hyped releases: GPT-5.1 and 5.2, Gemini 3, and Claude 4.5 and 4.6. To date, we’ve evaluated over 150 large language models, making this the most comprehensive longitudinal study of AI code security available.
Key Finding #1: The Security Ceiling Holds Firm
The headline number tells the story: across all models and all tasks, only 55% of generation tasks result in secure code. This means that in 45% of cases, the model introduces a known security flaw into the codebase.
What makes this finding particularly striking is the context. Over the same time period, these models have achieved near-perfect syntax correctness, now exceeding 95%. The gap between “code that works” and “code that works securely” isn’t just persisting; it’s widening.
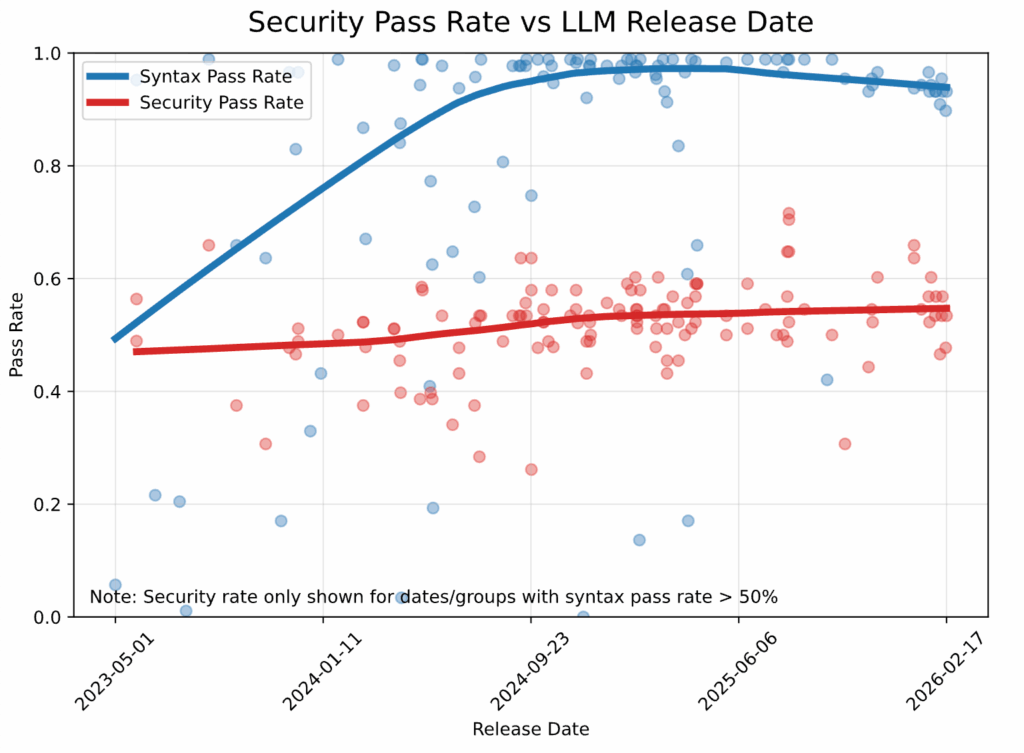
The data reveals a troubling trend: while syntax pass rates (shown in blue) have climbed steadily from about 50% to 95% since 2023, security pass rates (shown in red) have remained essentially flat, hovering between 45% and 55% regardless of model generation or release date.
Models have become excellent at writing code that compiles. They’ve failed at writing code that’s safe.
This isn’t a matter of insufficient training or inadequate model size. Our October 2025 update showed that model size has only a very small effect on security performance, and even that marginal difference has largely disappeared with more recent releases. Whether you’re using a 20-billion or 400-billion parameter model, security performance clusters around the same disappointing 55% mark.
Key Finding #2: The Languages Tell Different Stories
When we break down performance by programming language, we see significant variation… and some concerning trends.
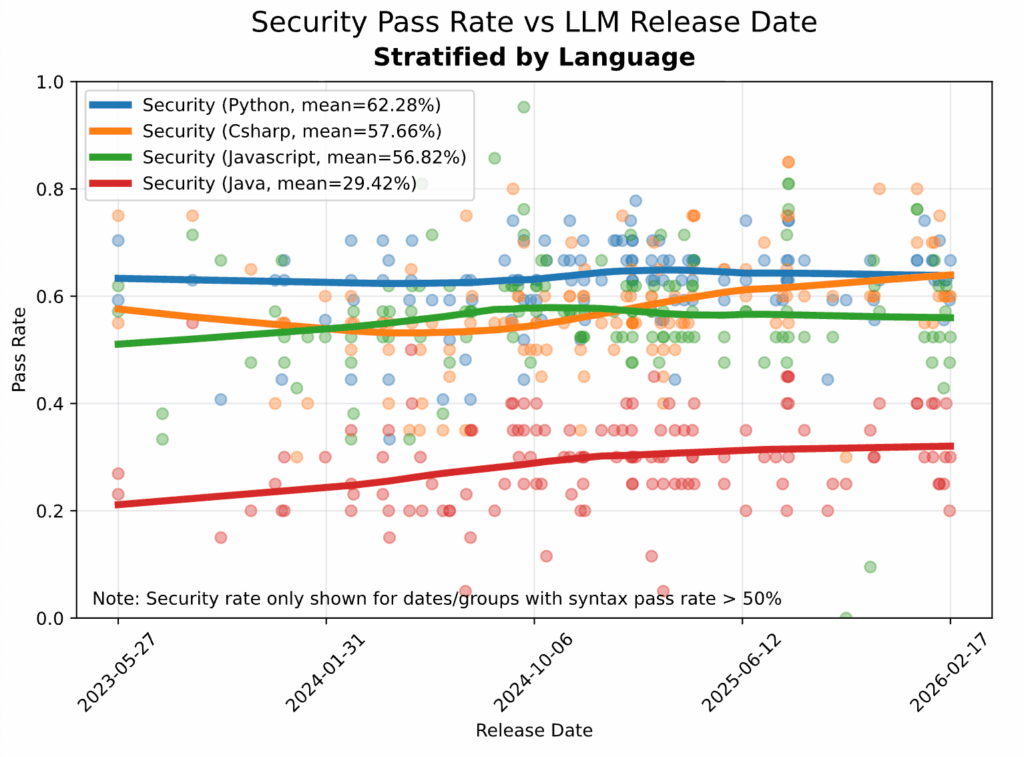
Performance breakdown:
- Python: 62% security pass rate (best performer, showing slight improvement)
- C#: 58% (modest gains over time)
- JavaScript: 57% (essentially flat)
- Java: 29% (worst performer)
The Java problem deserves special attention. Despite being a cornerstone of enterprise development and having decades of established security best practices, AI models are consistently failing to generate secure Java code. While other languages show modest improvements or stability, Java’s security pass rate has remained stubbornly low.
Why is Java uniquely problematic? Our hypothesis is that models are over-trained on legacy Java patterns – the millions of lines of older Java code in public repositories that predate modern security frameworks and best practices. When asked to write Java code, these models default to patterns learned from insecure legacy code rather than contemporary secure implementations.
The October report noted this phenomenon: “Somewhat surprisingly, many of the models perform much worse on the Java tasks, even for cases involving the CWEs that are generally easier to avoid, such as SQL injection”. This isn’t just a statistical quirk; it’s a critical vulnerability for enterprises heavily invested in Java-based systems.
Key Finding #3: The Vulnerability Profile Hasn’t Changed
Not all security vulnerabilities are created equal. When we examine performance by specific Common Weakness Enumeration (CWE) types, we see a stark divide that has persisted since our original study.
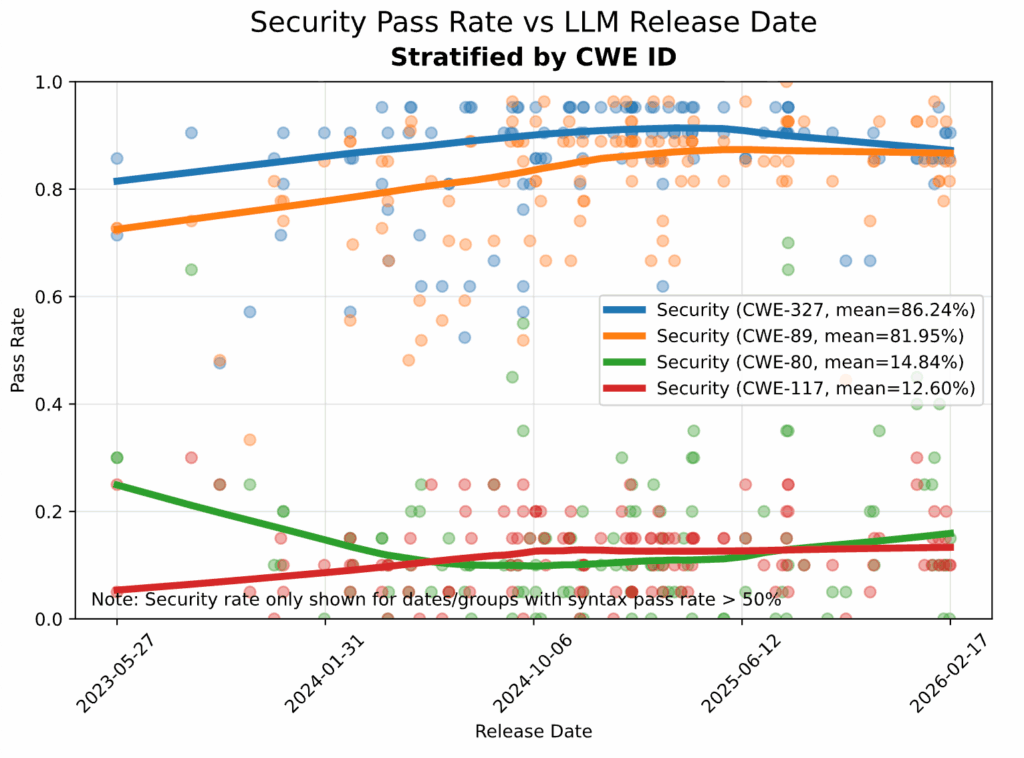
The “Easy Wins”:
- SQL Injection (CWE-89): 82% security pass rate
- Insecure Cryptographic Algorithms (CWE-327): 86% security pass rate
The Persistent Failures:
- Cross-Site Scripting (CWE-80): 15% security pass rate
- Log Injection (CWE-117): 13% security pass rate
These numbers have barely budged since our initial 2025 report. Our October update found that “for SQL injection and cryptographic algorithms models are performing relatively well and getting better. For cross-site scripting and log injection, models generally perform very poorly and appear to be getting worse”.
The pattern reveals something fundamental about how these models approach security. They excel at recognizing obvious, surface-level patterns, like parameterized SQL queries or standard encryption libraries. But they consistently fail at the more nuanced security challenges that require understanding dataflow across multiple lines or files.
Cross-site scripting and log injection vulnerabilities require tracking how user input flows through an application, identifying injection points, and implementing proper sanitization at the right boundaries. This type of reasoning demands context awareness that goes beyond pattern matching, and it’s precisely where current LLMs fall short.
As our original report noted, “doing complex [dataflow] analysis correctly consistently is difficult even for humans”. Expecting LLMs to excel at this without specific training or architectural improvements was perhaps optimistic. The data confirms: two years later, they still can’t do it reliably.
Key Finding #4: Model Hype ≠ Security Improvement
The gap between marketing promises and security reality has never been wider. Let’s examine the most hyped releases from the past six months:
OpenAI’s GPT-5.1 and 5.2 (“Code Red”): Despite the dramatic branding and claimed improvements in reasoning capabilities, these models’ security performance remains within the margin of error of GPT-4.1. No meaningful security gains materialized.
Google’s Gemini 3: Showed incremental improvements over Gemini 2.5, but still clusters firmly in the 55-60% security pass rate range—the same band we’ve seen for years.
Anthropic’s Claude 4.5 and 4.6: Demonstrably excellent at functional tasks and generating syntactically correct code, but security performance remains flat compared to earlier Claude generations.
There is one notable exception: OpenAI’s reasoning-focused models. Our October update documented that “OpenAI’s reasoning models posted the largest step-ups”. The GPT-5 series with extended reasoning achieved security pass rates between 70-72% — a meaningful improvement over the standard 55%.
However, even this represents the highest-performing category, and 70-72% is still far from acceptable for production security. A 28-30% vulnerability rate means roughly one in three AI-generated code snippets contains a security flaw. Would you accept those odds in your production environment?
The reasoning model exception does hint at a potential path forward: models that engage in more deliberate, step-by-step analysis before generating code show better security outcomes. The October report suggested that “reasoning steps function like an internal code review, increasing the chance of catching insecure constructs before output”. But even with this architectural advantage, we’re nowhere near the security reliability developers need.
Bottom line: Two years of “revolutionary” model releases have moved the security needle from approximately 55% to… approximately 55%. Marketing buzz about breakthrough capabilities hasn’t translated to meaningful security improvements.
Analysis: Why Are We Stuck?
Understanding why AI models consistently fail at security despite excelling at functionality requires examining four interconnected factors.
Reason #1: Training Data is Frozen in Time
Large language models learn to generate code by studying vast corpuses of existing code—primarily from public repositories like GitHub, Stack Overflow, and open-source projects. The fundamental problem: this training data reflects historical coding practices, including historical security flaws.
The internet’s code corpus hasn’t fundamentally changed. The same insecure patterns that existed in 2020 are present today. When models train on this data, they learn to replicate those patterns.
Consider what this means in practice: A model training on GitHub repositories will encounter thousands of examples of SQL queries constructed via string concatenation—a known anti-pattern that leads to SQL injection vulnerabilities. It will see far fewer examples of properly parameterized queries, especially in older codebases. The model learns from frequency, not correctness. It generates what it sees most often, not what’s most secure.
Until the underlying training data fundamentally shifts toward secure-by-default patterns, we shouldn’t expect dramatic improvements in model security performance.
Reason #2: Productivity Optimization ≠ Security Optimization
AI model development is driven by clear business incentives: speed to correct output, user satisfaction, and developer productivity. These metrics are easy to measure and directly impact adoption. Security, by contrast, is a non-functional requirement, harder to quantify, harder to reward during model training, and often invisible until it causes a real-world incident.
The market incentive structure is clear: companies compete on “time to working code,” not “time to secure code.” Developers love these tools because they dramatically accelerate the path from idea to implementation. Launch Tweets celebrate how quickly a developer built a full application using AI assistance. Nobody tweets about the security vulnerabilities lurking in that code – at least not until much later, when it’s compromised.
This misalignment runs deep. Model training objectives focus on functional correctness as judged by unit tests, code compilation, and user acceptance. Security isn’t typically part of the training feedback loop because secure code and insecure code are often functionally equivalent; they both “work” in the narrow sense that they produce the expected output for typical inputs.
The result: we’ve optimized for the wrong thing. We’ve built models that are phenomenal at generating functionally correct code quickly, with little regard for whether that code creates security vulnerabilities.
Reason #3: Security Requires Context, Not Just Pattern Matching
The persistent failure on cross-site scripting and log injection vulnerabilities reveals a fundamental limitation of current LLM architectures: they excel at recognizing local patterns but struggle with global context.
Consider these contrasting examples:
Pattern Matching (Where LLMs Excel): Identifying SELECT * FROM users WHERE id = ${id} as vulnerable to SQL injection is fundamentally a pattern-recognition task. The model has seen this exact pattern flagged as insecure countless times in training data, code reviews, and security guides. When it encounters a similar pattern, it can often (though not always) avoid it or suggest a parameterized alternative.
Contextual Reasoning (Where LLMs Fail): Properly sanitizing user input that flows through multiple function calls, gets stored in a variable, passes through a transformation function, and is eventually rendered in a web template requires understanding dataflow across potentially dozens of lines and multiple files. The model must track where the data comes from, what transformations it undergoes, and where it ultimately gets used, then determine whether each step maintains security invariants.
This is precisely the type of analysis that humans find challenging and that our tools (like SAST) are specifically designed to perform. Current LLMs simply aren’t architected to maintain the kind of persistent state and inter-statement reasoning required for robust dataflow analysis.
As our original report noted when discussing why LLMs struggle with certain vulnerability types, this reflects a core limitation in how these models process and generate code.
Reason #4: The “Works First, Secure Later” Development Culture
AI coding assistants don’t operate in a vacuum; they’re shaped by and reinforce existing developer workflows and cultural norms. The dominant development pattern remains: get it working first, then refine. In practice, “refine” rarely includes thorough security review, especially under deadline pressure.
These AI tools are optimized for this exact workflow. They’re designed to help developers rapidly prototype functionality, get to a working state quickly, and iterate based on immediate feedback. This is precisely what makes them valuable for productivity. But it also means they’re amplifying a development culture that treats security as an afterthought rather than a foundational requirement.
The mainstreaming effect multiplies this problem. As adoption of AI coding assistants grows from early adopters to the mainstream developer population, we’re seeing more code generated faster than ever before. Without corresponding improvements in security, this means more vulnerabilities, created more quickly, at greater scale.
The productivity-security paradox: The same tools that make developers more productive are helping them generate insecure code faster than ever before.
Conclusion: The Productivity-Security Gap
We stand at a critical juncture in software development. AI coding assistants have demonstrably transformed developer productivity, enabling individuals and teams to build functionality faster than ever before. The technical capabilities are impressive, the adoption is accelerating, and the productivity gains are real.
But we’ve built these tools with a dangerous blind spot. Two years of “revolutionary” model releases have moved the security needle from approximately 55% to… approximately 55%. The gap between nearly perfect syntax correctness (95%+) and mediocre security performance (55%) represents a fundamental misalignment in how these models are built, trained, and deployed.
This divergence should concern everyone involved in software development. As AI coding tools become ubiquitous (integrated into IDEs, adopted across enterprises, and used by developers at every skill level), we risk scaling insecure code at unprecedented velocity. The very productivity gains we celebrate could be undermining the security of the software ecosystem.
The data suggests four key conclusions:
First, the training data problem is real and persistent. Until models are trained on corpuses that prioritize secure code examples, we shouldn’t expect dramatic security improvements.
Second, market incentives are misaligned. The race to build faster, more capable coding assistants has overlooked security as a core competency. Speed to working code isn’t the same as speed to secure code.
Third, current LLM architectures have fundamental limitations for security tasks. Pattern matching works for simple vulnerabilities, but the complex dataflow analysis required for XSS and injection detection remains beyond reach.
Fourth, cultural and workflow factors amplify the problem. AI tools are being integrated into development processes that already treated security as an afterthought. We’re automating bad habits at scale.
The path forward requires acknowledging these realities and building compensating controls:
- Acknowledge the gap between functionality and security in current AI models
- Design workflows that don’t assume AI-generated code is secure by default
- Demand better from AI vendors, with transparent security benchmarking and security-first training
- Build security into the process through mandatory SAST integration, security-focused prompting, and rigorous code review
- Maintain the human responsibility for code security, regardless of whether an AI wrote the initial version
The models that are revolutionizing how we write code haven’t revolutionized how securely we write it. Until they do, the human security review remains irreplaceable. Developer productivity and code security need not be in tension, but achieving both requires deliberate design, better tooling, and organizational commitment to treating security as a first-class concern in the age of AI-assisted development.
The productivity revolution is here. The security revolution isn’t. That gap defines the challenge ahead.
For full methodology, please see the 2025 GenAI Code Security Report, updated in October.
This research was conducted by Veracode’s Security Research team.
Related Posts

