GPT‑5 Pulls Ahead on Secure Code While Rivals Stall

AI coding assistants are evolving quickly. But are the latest models any better at writing secure code? Our October 2025 analysis brings fresh data on how newer large language models (LLMs) stack up against their predecessors, and the results reveal both progress and persistent gaps.
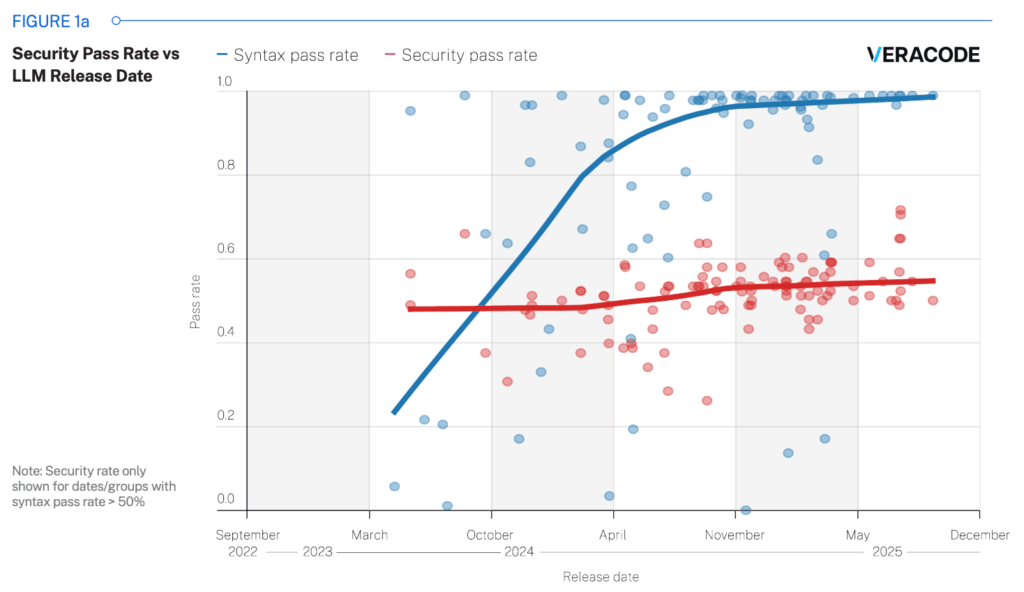
This update builds on our July 2025 GenAI Code Security Report, which tested over 100 LLMs across four major programming languages. Using the same 80-task benchmark, we evaluated the newest models released through October 2025. What we found: significant gains from one provider, while most others remained stagnant.
OpenAI’s Reasoning Models Lead the Pack
For the first time since we began tracking AI-generated code security, we’ve seen a meaningful performance jump – but only from OpenAI‘s latest GPT-5 reasoning models.
GPT-5 Mini achieved a 72% security pass rate, the highest we’ve recorded. The larger GPT-5 model followed closely at 70%. These results represent a substantial improvement over previous generations, which typically scored between 50-60%.
What sets these models apart? They’re designed to “think through” problems internally before producing output – a process similar to code review. This extra reasoning step appears to catch insecure patterns that standard models miss.
Interestingly, GPT-5-chat, OpenAI’s latest non-reasoning model, scored just 52%, well below their reasoning variants. This gap suggests that OpenAI’s reasoning alignment may be driving the security gains, not simply model scale or training data updates.
Other Providers Show No Improvement
Models from Anthropic, Google, Qwen, and xAI released between July and October 2025 did not show meaningful security improvements. In fact, some performed slightly worse:
- Anthropic’s Claude Sonnet 4.5: 50% (down from Claude Sonnet 4’s 53%)
- Anthropic’s Claude Opus 4.1: 49% (down from Claude Opus 4’s 50%)
- Google Gemini 2.5 Pro: 59%
- Google Gemini 2.5 Flash: 51%
- Qwen3 Coder models: 50%
- xAI Grok 4: 55%
These results cluster in the same 50-59% range we observed in our original July analysis. The lack of progress indicates that simply scaling models or updating training data isn’t enough to improve security outcomes.
Language-Specific Improvements
Breaking down the results by programming language reveals targeted progress:
C# and Java saw notable security gains in newer models. This suggests AI labs are tuning their training data or fine-tuning processes to favor enterprise coding languages, where secure code is often mission-critical.
Python and JavaScript remained relatively flat, with security performance hovering near previous levels.
This language-specific trend aligns with enterprise priorities. Organizations using Java and C# for backend services and financial systems may benefit most from the latest models.
Vulnerability Trends: SQL Injection Gets Better, Others Don’t
Performance varied sharply by vulnerability type:
- SQL Injection (CWE-89): Newer models showed modest improvement, likely reflecting cleaner training data as developers increasingly adopt prepared statements and parameterized queries.
- Cross-Site Scripting (CWE-80): No improvement. Models continue to struggle with output sanitization, scoring below 14% on average.
- Log Injection (CWE-117): Similarly poor, with pass rates around 12%.
- Cryptographic Algorithms (CWE-327): Strong performance continued, with pass rates above 85%.
The persistent failures in Cross-Site Scripting (XSS) and log injection highlight a fundamental limitation: LLMs can’t reliably determine which variables contain untrusted data without extensive context. Even with larger context windows, models lack the interprocedural dataflow analysis needed to make these decisions accurately.
Reasoning Models Outperform Standard Models
Across all providers, models that use internal reasoning before output averaged higher security pass rates than their non-reasoning counterparts. This pattern was consistent even among OpenAI’s GPT-5 variants.
Why does reasoning help? The most likely explanation is that reasoning steps function like an internal code review. The model evaluates multiple implementation options and filters out insecure patterns before committing to an answer. This mirrors how human developers improve code quality through peer review.
Standard models, by contrast, generate code in a single forward pass, selecting implementations based on probabilistic patterns in training data—which often includes insecure code.
Why the Divergence Between Providers?
Two factors likely explain OpenAI’s gains while others stagnated:
1. Explicit Security Training
OpenAI’s GPT-5 model documentation includes performance metrics on security “capture-the-flag” challenges, where LLMs attempt to find and exploit vulnerabilities. This suggests OpenAI treats offensive security skills as a performance indicator and likely includes security-focused examples in training data or fine-tuning.
Most other providers have not emphasized red-teaming capabilities to the same degree. In fact, many LLMs are tuned to refuse requests for potentially harmful security techniques—a safety measure that may inadvertently reduce their ability to reason about secure coding patterns.
2. Security-Oriented Reasoning Alignment
The strong performance of GPT-5’s reasoning models (and the weak performance of GPT-5-chat – the non-reasoning variant) suggests that OpenAI’s reasoning alignment process specifically improves security outcomes. It’s possible their tuning examples include high-quality secure code or explicitly teach models to reason about security trade-offs.
Other providers may not have prioritized security in their reasoning alignment, focusing instead on general problem-solving or mathematical reasoning.
What This Means for Development Teams
These results underscore three critical takeaways:
1. Reasoning models offer a real advantage for security. If you’re using AI coding assistants, opt for reasoning-enabled models when available. The extra latency may be worth the reduced vulnerability risk.
2. Security performance remains highly variable. Even the best-performing models in this update still introduce vulnerabilities in 28% of cases. Organizations cannot rely on AI-generated code to be secure by default.
3. Layered security controls remain essential. AI coding assistants are tools, not replacements for comprehensive security programs. Static analysis (SAST), software composition analysis (SCA), code review, posture management, and runtime protections are still required to secure modern applications.
The Path Forward
The progress from OpenAI’s reasoning models is encouraging, but it also highlights how far the industry has to go. A 72% security pass rate is a step forward – but it still means more than one in four coding tasks introduce a known vulnerability.
As AI models continue to evolve, we expect to see more emphasis on security-specific training and reasoning alignment. However, the fundamental challenge remains: training data scraped from the internet contains both secure and insecure code, and models learn both patterns equally well.
Until AI labs prioritize security in training and alignment processes, developers and security teams must treat AI-generated code as untrusted input. Validate it. Scan it. Review it. Just as you would any other code contribution.
Get the Data on the Latest GenAI Code Security
This update reflects testing conducted in October 2025 using our standardized 80-task benchmark. For complete methodology details, longitudinal trends, and the full dataset, download the updated GenAI Code Security Report.
