Comparing vulnerable methods with static analysis

In this blog post, we will talk a bit about traditional static analysis – what it is, what it’s used for, and where our vulnerable methods analysis fits in amongst the other kinds of static analysis.
Wikipedia tells us:
Static program analysis is the analysis of computer software that is performed without actually executing programs
Why wouldn’t we want to execute a program in order to analyze it? The main reason is that we gain stronger guarantees about whether our analyses will terminate (modulo bugs in it). Testing a program by executing it can only ever reveal the presence of bugs in paths that are exercised during the execution, on the other hand, static analysis can reason about all possible paths in the program.
A static analysis tells us about the possible runtime behavior of programs. What it computes is essentially an approximation — it cannot have knowledge of the exact inputs a program receives at runtime, for example, so it can only operate based on abstractions of them. This may lead to false positives or false negatives, depending on how conservative or permissive an analysis is. Advancing the accuracy of current analysis techniques is an active area of research.
Static analyses are usually found in compilers, IDEs, linters, and standalone agents (like SourceClear’s CI agent) that run as part of a continuous integration pipeline. They detect errors, discover properties about programs, and help us write better programs in general.
Static analysis and security
When applied to security, the goal of a static analysis is usually to identify how vulnerabilities propagate into the sensitive parts of a system.
To borrow terms from data-flow analysis, we are concerned with sources, where the influence of a vulnerability begins, and how it spreads into sinks, the places it must reach to cause harm. A classic example of this is taint analysis, which is concerned with malicious user inputs making their way into critical areas, such as a database or shell.
In the context of web applications, the sources are any user-controlled input: query parameters, request parameters, cookies, and so on. As an example consider the following code:
<?php
$user = $_GET['user'];Here, $user is considered tainted, as it comes from an insecure source and/or is user-controlled. Taint propagates by usage, so any value that depends on the tainted value is itself tainted:
$query = "select * from users where username = '" . $user . "'";
$filename = "/files/" . $user . ".txt";A taint analysis would consider both $query and $filename as tainted, and track how tainted values propagate into sinks: database queries, file inclusions, shell commands, logs, and so on:
include($filename);
mysql_query($query);In order for tainted data to propagate safely into a sink, it must be sanitized. Taint analysis will ensure that this step is never forgotten.
// This is safe
$safe_query = mysql_real_escape_string($query);
mysql_query($safe_query);Taint analysis is an application of the more general data-flow analysis, which operates over a control-flow graph representation of programs.
Vulnerable methods
This brings us back to vulnerable methods. How exactly is it different from taint analysis, and where does it stand with respect to other kinds of static analysis?
It is security-related, which means it operates principally on sources and sinks as well: vulnerable open source libraries in the wild can be thought of as the sources, and the points in a user program which call vulnerable methods of dependencies as the sinks.
We want to ensure that call chains leading from the user program to vulnerable dependencies are picked up as precisely as possible. For this, we require a call graph, an abstraction of a control-flow graph to take into account only method calls.
Using the call graph, we can determine unambiguously if a path from user code to vulnerable methods exists. The accuracy of this depends on how precisely the call graph is constructed, which we constantly work on improving. As an example, consider the call graph from a project below:
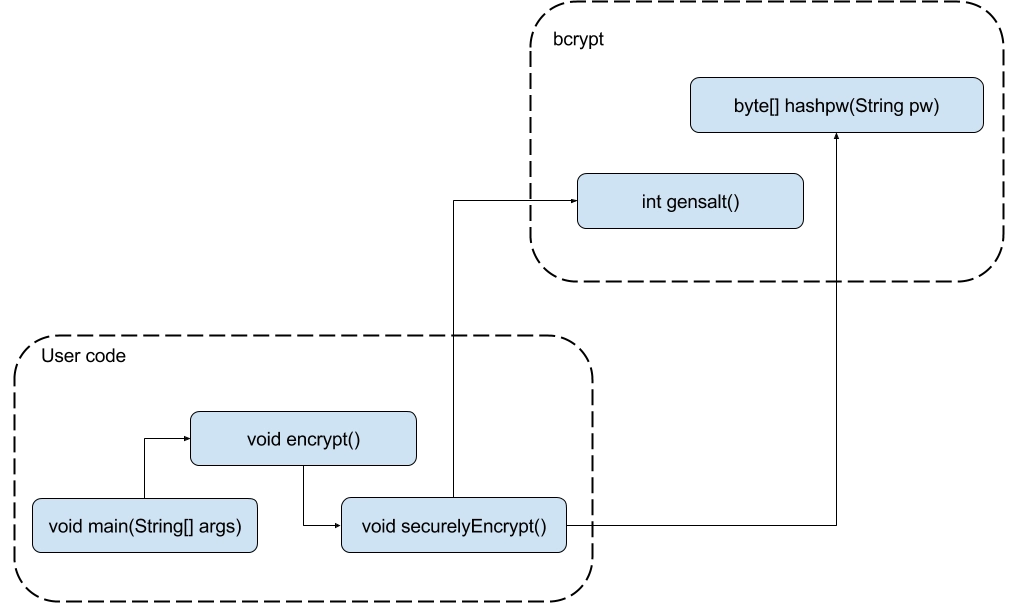
The main() method inside user’s code calls the encrypt() method which in turn calls securelyEncrypt() and eventually the call chain terminates at the hashpw() method of the bcrypt library. One novel aspect of the vulnerable methods analysis as implemented by SourceClear is that we do a library modulo analysis, i.e. We compute all possible call chains to a vulnerable method in a library in advance and when we analyse a user’s project we just use this information. This distinction is critical, as one of the major problems with traditional static analysis is their inability to scale with large projects (or when including all libraries in the analysis).
Rule-based analysis
To further characterize what we do, we’ll look at another form of analysis: rule-based ones which inspect the abstract syntax trees of programs, looking for patterns and reporting potential matches. This is perhaps the most widely-used kind of analysis, because it’s relatively simple to implement, extend, and use. It’s well-represented in lots of languages, with FindBugs and PMD (Java), Bandit (Python), Brakeman and Flog (Ruby), ESLint (JavaScript), and so on.
The kind of rules range from simple checks to complex patterns. For example, PMD will complain about the age field in this class, suggesting that it be final.
public class Person {
static int age;
}ESLint knows about JavaScript operator precedence and will report potential errors:
if (!key in object) {
// Condition is equivalent to ((!key) in object)
// ...
}While useful for enforcing style guidelines and picking up some security violations, rule-based systems usually report matches without considering context. In other words, they function on a purely syntactic level and do not track control flow.
Such a system could probably inform you if a request parameter was being used in a sink:
include($_GET['user']);… but without tracking control flow, more levels of indirection would obscure its ability to deal with more complex cases:
function getUser() {
return $_GET['user'];
}
$user = getUser();
include($user);In a sense, these sorts of analysis can be thought of as being concerned with sources only, with the rest of the program trivially being the sink. This over approximation usually leads to a high rate of false positives in practice.
Conclusion
When applied to security, static analysis tends to be concerned about sources of vulnerabilities and the sinks they may flow into.
We discussed the relative merits of taint analysis, our vulnerable methods analysis, and simple rule-based analyses, as well as the techniques underlying them, such as data-flow analysis and control-flow graphs.
These techniques can be compared in a very general way in terms of generality.
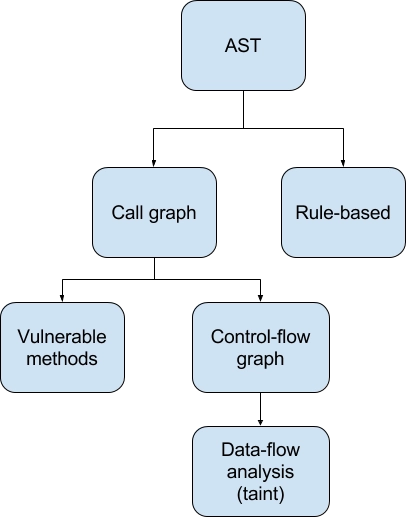
Parent nodes in this tree are more general than children: a more general analysis can be applied much more easily and to a wider domain of problems, but is generally less accurate and useful.
We’ll also try to characterize them in this table below based on how they are applied:
| taint | vulnerable-methods | rule-based | |
|---|---|---|---|
| Program abstraction | control-flow graph | call graph | AST |
| Type of code | first-party | third-party | first-party |
| Patterns | generic | specific | generic |
| Rate of false positives | low | low | high |
What we can see from all this is that these techniques are distinct, and are useful in different scenarios but the vulnerable methods analysis provides a nice balance of precision and accuracy when applied to third-party code.
All these tools aim to improve code quality, and SourceClear’s vulnerable methods analysis presents a new design point in the space of static analysis, it provides more comprehensive coverage about 3rd party vulnerabilities and you should consider adding to your continuous integration pipeline.

